Deploy this version
- Docker
- Pip
docker run litellm
docker run
-e STORE_MODEL_IN_DB=True
-p 4000:4000
ghcr.io/berriai/litellm:main-v1.65.4-stable
pip install litellm
pip install litellm==1.65.4.post1


docker run
-e STORE_MODEL_IN_DB=True
-p 4000:4000
ghcr.io/berriai/litellm:main-v1.65.4-stable
pip install litellm==1.65.4.post1
v1.65.0-stable is live now. Here are the key highlights of this release:
This release introduces support for centrally adding MCP servers on LiteLLM. This allows you to add MCP server endpoints and your developers can list and call MCP tools through LiteLLM.
Read more about MCP here.
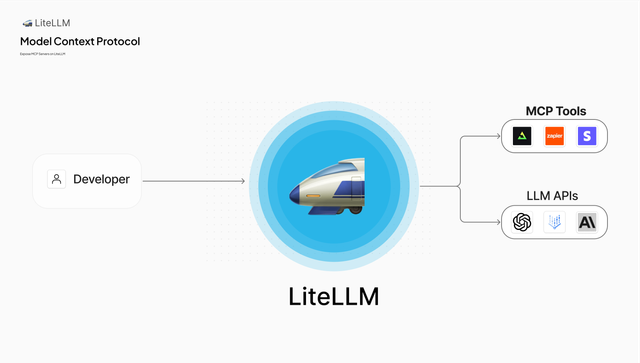
Expose and use MCP servers through LiteLLM
This release brings the ability to view total usage analytics even after exceeding 1M+ logs in your database. We've implemented a scalable architecture that stores only aggregate usage data, resulting in significantly more efficient queries and reduced database CPU utilization.
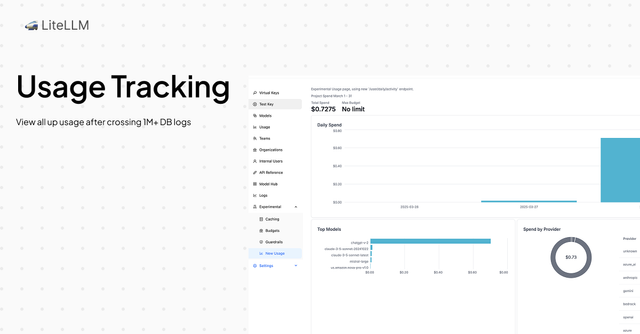
View total usage after 1M+ logs
How this works:
Daily Spend Breakdown API:
Retrieve granular daily usage data (by model, provider, and API key) with a single endpoint. Example Request:
curl -L -X GET 'http://localhost:4000/user/daily/activity?start_date=2025-03-20&end_date=2025-03-27' \
-H 'Authorization: Bearer sk-...'
{
"results": [
{
"date": "2025-03-27",
"metrics": {
"spend": 0.0177072,
"prompt_tokens": 111,
"completion_tokens": 1711,
"total_tokens": 1822,
"api_requests": 11
},
"breakdown": {
"models": {
"gpt-4o-mini": {
"spend": 1.095e-05,
"prompt_tokens": 37,
"completion_tokens": 9,
"total_tokens": 46,
"api_requests": 1
},
"providers": { "openai": { ... }, "azure_ai": { ... } },
"api_keys": { "3126b6eaf1...": { ... } }
}
}
],
"metadata": {
"total_spend": 0.7274667,
"total_prompt_tokens": 280990,
"total_completion_tokens": 376674,
"total_api_requests": 14
}
}
response_cost when using litellm python SDK with LiteLLM Proxy PRmax_completion_tokens on Mistral API PRlitellm_model_name on StandardLoggingPayload Docsv1.65.0 updates the /model/new endpoint to prevent non-team admins from creating team models.
This means that only proxy admins or team admins can create team models.
/model/update to update team models./model/delete to delete team models.user_models_only param to /v2/model/info - only return models added by this user.These changes enable team admins to add and manage models for their team on the LiteLLM UI + API.
These are the changes since v1.63.11-stable.
This release brings:
docker run
-e STORE_MODEL_IN_DB=True
-p 4000:4000
ghcr.io/berriai/litellm:main-v1.63.14-stable.patch1
Here's a Demo Instance to test changes:
arn:aws:bedrock:us-east-1:...)/v1/completions Get Startedus.deepseek.r1-v1:0 model name DocsOPENROUTER_API_BASE env var support Docslitellm_proxy/ - support reading litellm response cost header from proxy, when using client sdk default_user_id user does not exist in DB PRSTORE_MODEL_IN_DB is True PRThese are the changes since v1.63.2-stable.
This release is primarily focused on:
docker run
-e STORE_MODEL_IN_DB=True
-p 4000:4000
ghcr.io/berriai/litellm:main-v1.63.11-stable
Here's a Demo Instance to test changes:
azure/eu and azure/us models
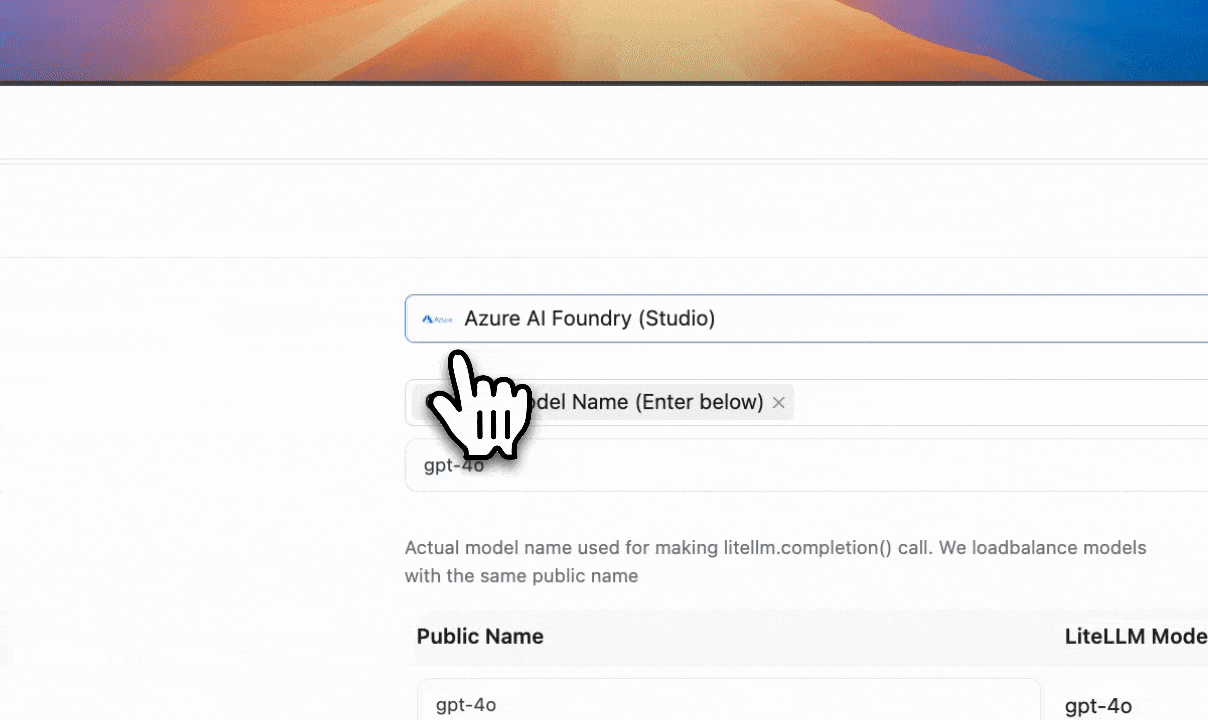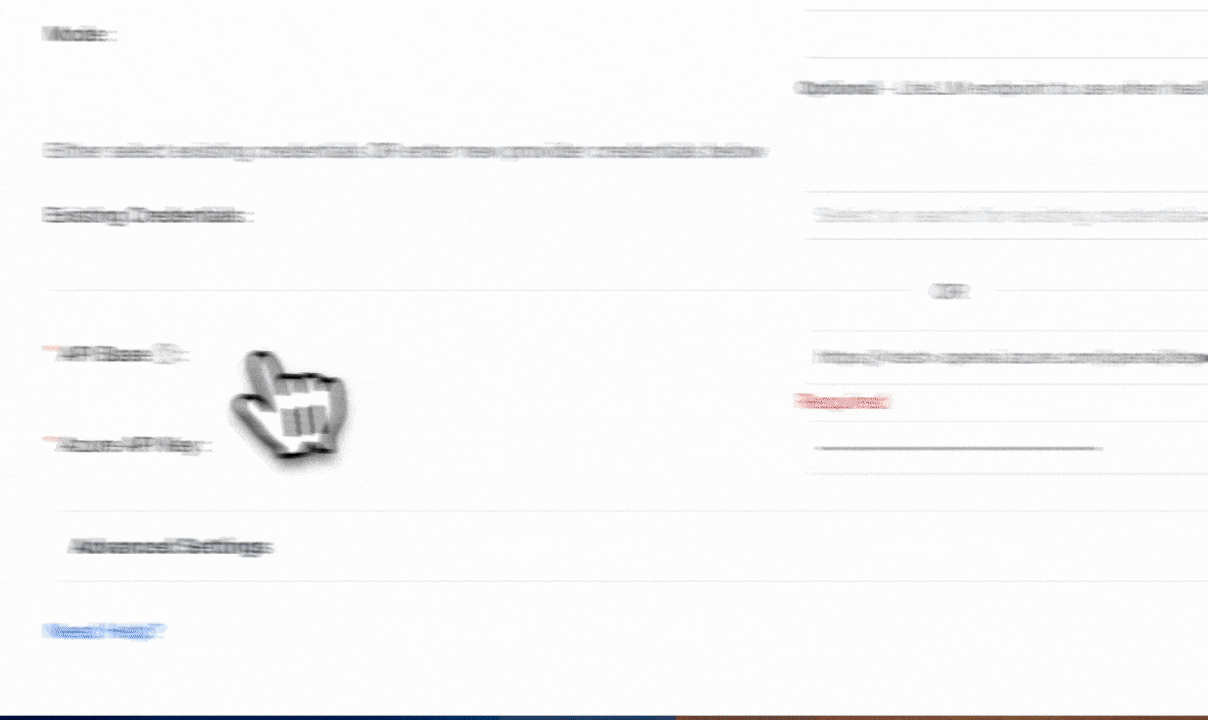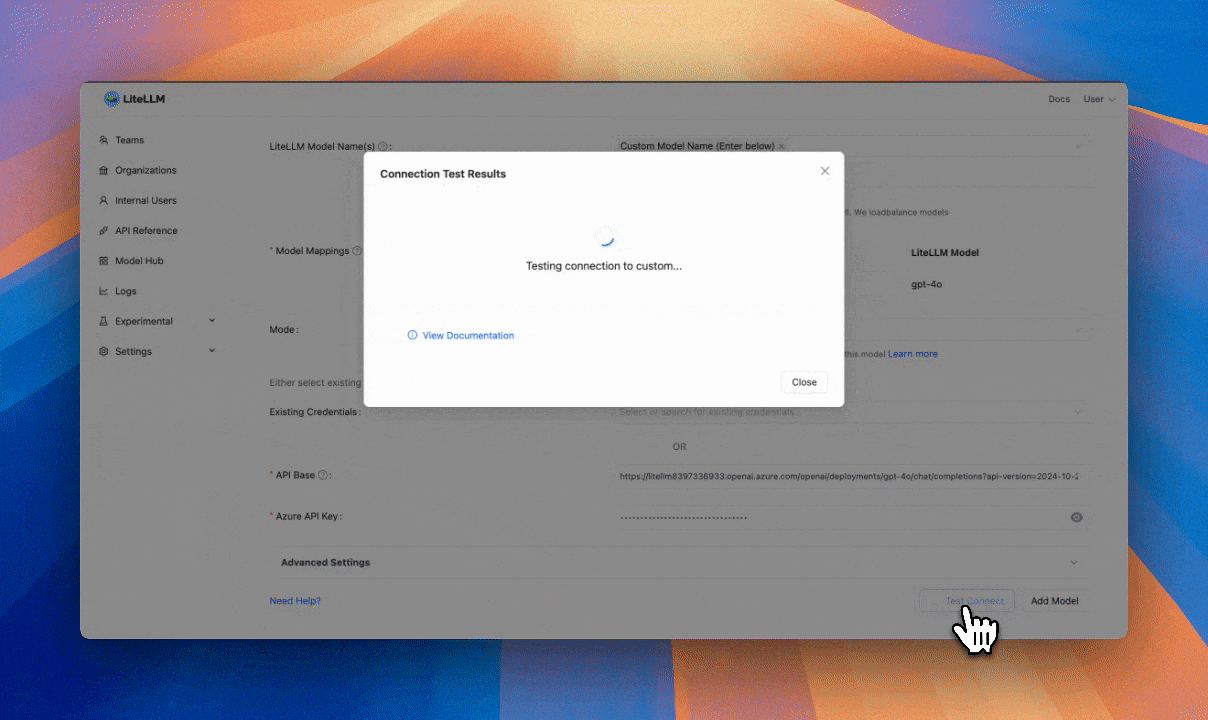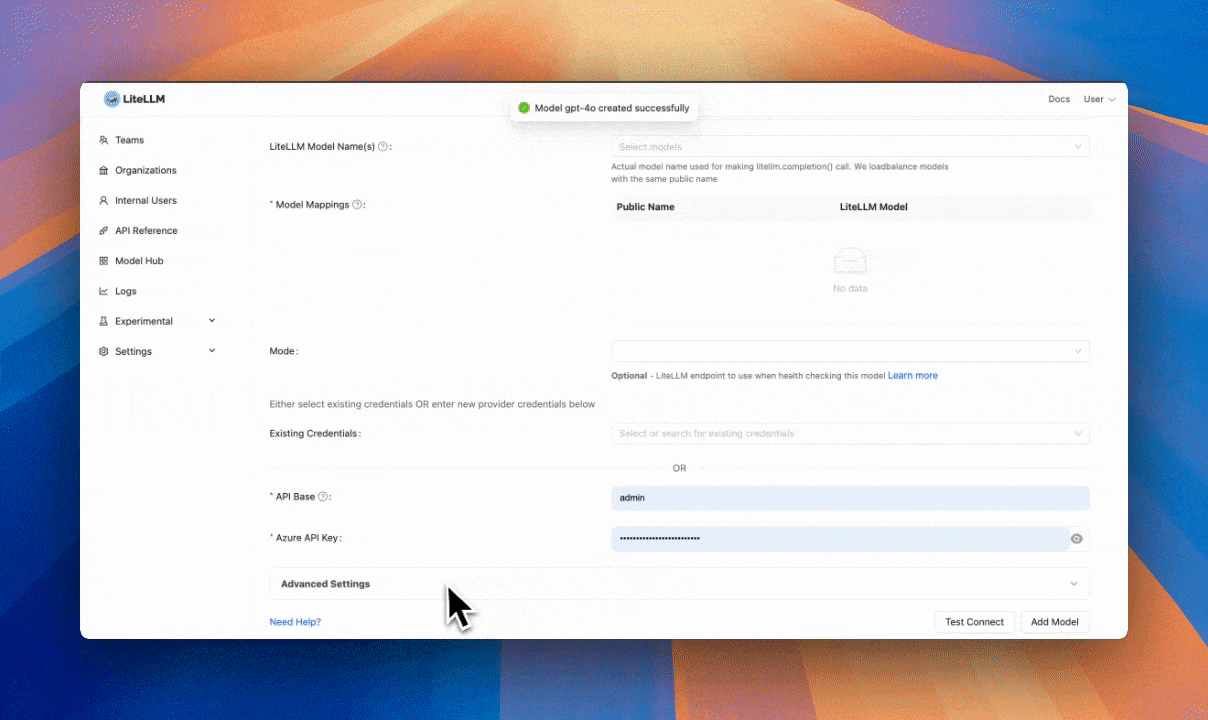
/responses API. Getting Startedreasoning_content on streaming Getting Startedcode, param and type on bad request error More information on litellm exceptions2025-02-01-preview PRdata: stripped from entire content in streamed responses PRYou can now onboard LLM provider credentials on LiteLLM UI. Once these credentials are added you can re-use them when adding new models Getting Started
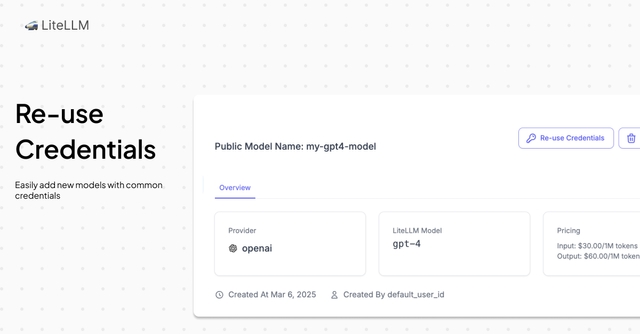
Before adding a model you can test the connection to the LLM provider to verify you have setup your API Base + API Key correctly
PROXY_LOGOUT_URL when set Getting Startedinternal_user_viewer role to see Test Key Page or Create Key Button More information on role based access controlsthinking tokensthinking tokens on OpenWebUI (Bedrock, Anthropic, Deepseek) Getting Started

These are the changes since v1.61.20-stable.
This release is primarily focused on:
thinking content improvements)This release will be live on 03/09/2025

Here's a Demo Instance to test changes:
supports_pdf_input for specific Bedrock Claude models PReu models PR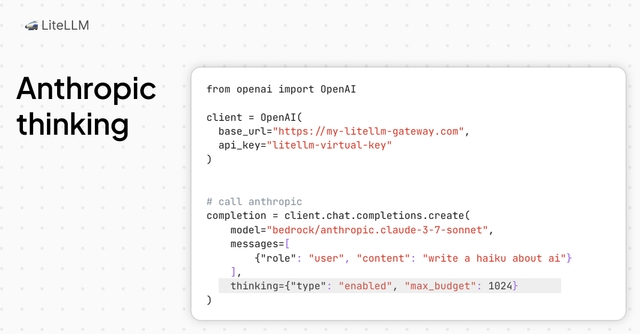
/openai/ passthrough for Assistant endpoints. Get Starteddescription if set in response_format. Get Startedsignature on streaming. Get Startedsignature_delta to signature. Read more/v1/messages endpoint - thinking param support. Get Started/v1/messages endpoint, to just work for the Anthropic API. 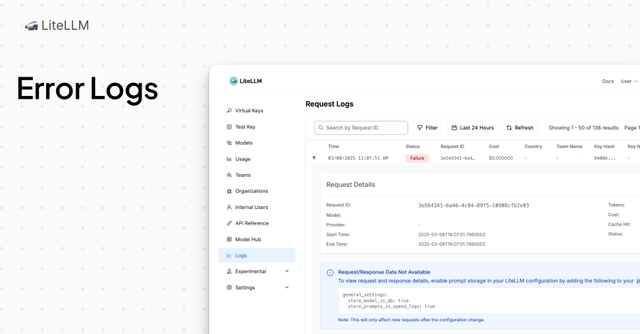
/embeddings, /image_generation, etc.). Get Startedv1.63.0 fixes Anthropic 'thinking' response on streaming to return the signature block. Github Issue
It also moves the response structure from signature_delta to signature to be the same as Anthropic. Anthropic Docs
"message": {
...
"reasoning_content": "The capital of France is Paris.",
"thinking_blocks": [
{
"type": "thinking",
"thinking": "The capital of France is Paris.",
- "signature_delta": "EqoBCkgIARABGAIiQL2UoU0b1OHYi+..." # 👈 OLD FORMAT
+ "signature": "EqoBCkgIARABGAIiQL2UoU0b1OHYi+..." # 👈 KEY CHANGE
}
]
}
These are the changes since v1.61.13-stable.
This release is primarily focused on:
Here's a Demo Instance to test changes:
<think> param extraction into ‘reasoning_content’ Start herelitellm_proxy/ for embedding, image_generation, transcription, speech, rerank Start hereView the complete git diff here.
Get a 7 day free trial for LiteLLM Enterprise here.
no call needed
/image/variations endpoint BETA support Docs/image/variations BETA endpoint Docs-latest tag in model for cost calculationgemini/) - support gemini 'frequency_penalty' and 'presence_penalty'metadata param preview support litellm.enable_preview_features = True litellm_settings::enable_preview_features: true supported_ as base model user passed in request body is int instead of string /key/delete - allow team admin to delete team keys /key/update - new temp_budget_increase and temp_budget_expiry fields - Start Herelitellm_overhead_latency_metric litellm_team_budget_reset_at_metric and litellm_api_key_budget_remaining_hours_metric /health/services endpoint. Start Herex-litellm-timeout x-litellm-attempted-retriesx-litellm-overhead-duration-ms x-litellm-response-duration-ms enforce_rbac param,allows proxy admin to prevent any unmapped yet authenticated jwt tokens from calling proxy. Start Herex-litellm-timeout param from request headers. Enables model timeout control when using Vercel’s AI SDK + LiteLLM Proxy. Start Hererole based permissions for model authentication. See HereThis is the diff between v1.57.8-stable and v1.59.8-stable.
Use this to see the changes in the codebase.
Get a 7 day free trial for LiteLLM Enterprise here.
no call needed
You can now view messages and response logs on Admin UI.

How to enable it - add store_prompts_in_spend_logs: true to your proxy_config.yaml
Once this flag is enabled, your messages and responses will be stored in the LiteLLM_Spend_Logs table.
general_settings:
store_prompts_in_spend_logs: true
Added messages and responses to the LiteLLM_Spend_Logs table.
By default this is not logged. If you want messages and responses to be logged, you need to opt in with this setting
general_settings:
store_prompts_in_spend_logs: true
alerting, prometheus, secret management, management endpoints, ui, prompt management, finetuning, batch
/utils/token_counter - useful when checking token count for self-hosted models /v1/completion endpoint as well omni-moderation-latest support. Start Herestream=true is passed, the response is streamed. Start HerePagerDuty Alerting Integration.
Handles two types of alerts:
Added support for tracking latency/spend/tokens based on custom metrics. Start Here
Support for reading credentials + writing LLM API keys. Start Here
ATHINA_BASE_URLThis is the diff between v1.56.3-stable and v1.57.8-stable.
Use this to see the changes in the codebase.
langfuse, management endpoints, ui, prometheus, secret management
Langfuse Prompt Management is being labelled as BETA. This allows us to iterate quickly on the feedback we're receiving, and making the status clearer to users. We expect to make this feature to be stable by next month (February 2025).
Changes:
Managing teams and organizations on the UI is now easier.
Changes:
/team/member_updateWe now support writing LiteLLM Virtual API keys to Hashicorp Vault.
Define custom prometheus metrics, and track usage/latency/no. of requests against them
This allows for more fine-grained tracking - e.g. on prompt template passed in request metadata
docker image, security, vulnerability

cgr.dev/chainguard/python:latest-devTo ensure there are 0 critical/high vulnerabilities on LiteLLM Docker Image
apt-getInstead of apt-get use apk, the base litellm image will no longer have apt-get installed.
You are only impacted if you use apt-get in your Dockerfile
# Use the provided base image
FROM ghcr.io/berriai/litellm:main-latest
# Set the working directory
WORKDIR /app
# Install dependencies - CHANGE THIS to `apk`
RUN apt-get update && apt-get install -y dumb-init
Before Change
RUN apt-get update && apt-get install -y dumb-init
After Change
RUN apk update && apk add --no-cache dumb-init
deepgram, fireworks ai, vision, admin ui, dependency upgrades
New Speech to Text support for Deepgram models. Start Here
from litellm import transcription
import os
# set api keys
os.environ["DEEPGRAM_API_KEY"] = ""
audio_file = open("/path/to/audio.mp3", "rb")
response = transcription(model="deepgram/nova-2", file=audio_file)
print(f"response: {response}")
LiteLLM supports document inlining for Fireworks AI models. This is useful for models that are not vision models, but still need to parse documents/images/etc.
LiteLLM will add #transform=inline to the url of the image_url, if the model is not a vision model See Code
Test Key Tab displays model used in response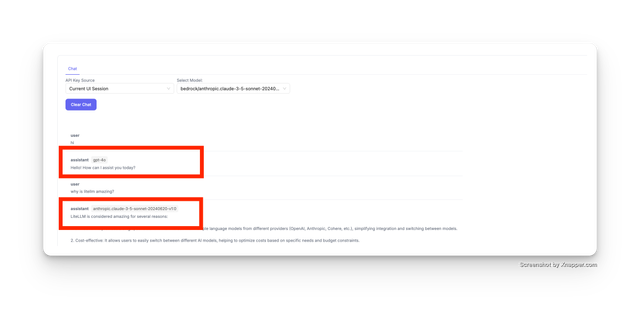
Test Key Tab renders content in .md, .py (any code/markdown format)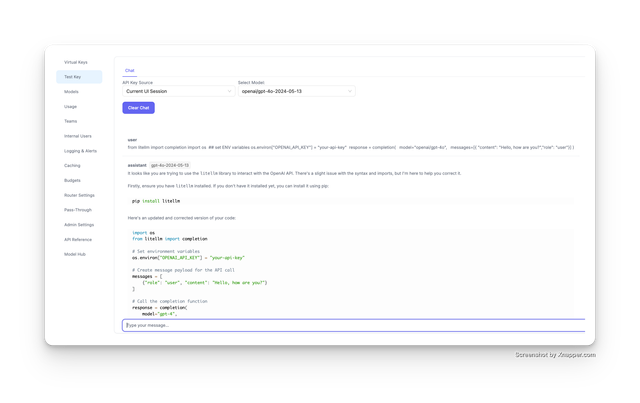
fastapi==0.115.5 https://github.com/BerriAI/litellm/pull/7447guardrails, logging, virtual key management, new models
Get a 7 day free trial for LiteLLM Enterprise here.
no call needed
Track guardrail failure rate and if a guardrail is going rogue and failing requests. Start here
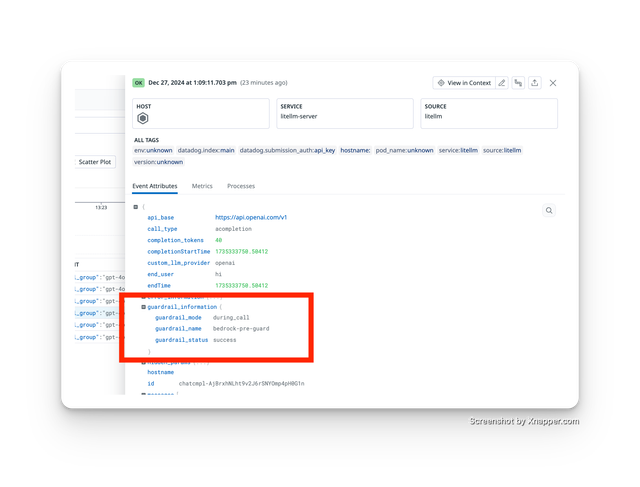
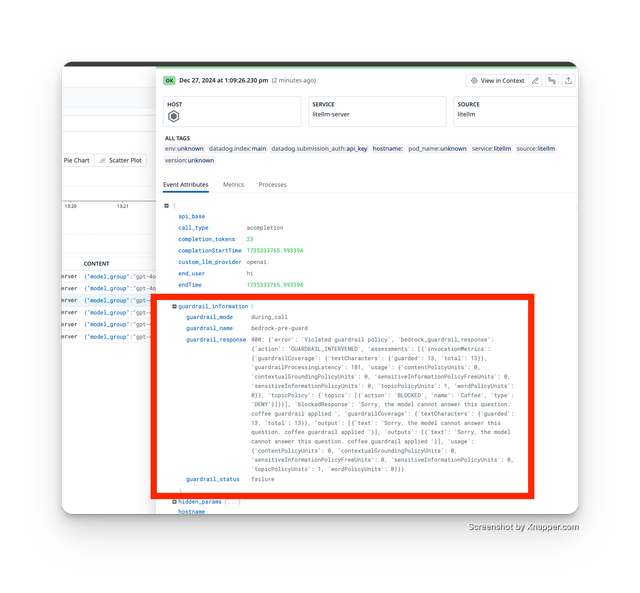
/guardrails/list/guardrails/list allows clients to view available guardrails + supported guardrail params
curl -X GET 'http://0.0.0.0:4000/guardrails/list'
Expected response
{
"guardrails": [
{
"guardrail_name": "aporia-post-guard",
"guardrail_info": {
"params": [
{
"name": "toxicity_score",
"type": "float",
"description": "Score between 0-1 indicating content toxicity level"
},
{
"name": "pii_detection",
"type": "boolean"
}
]
}
}
]
}
Send mock_response to test guardrails without making an LLM call. More info on mock_response here
curl -i http://localhost:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-npnwjPQciVRok5yNZgKmFQ" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{"role": "user", "content": "hi my email is ishaan@berri.ai"}
],
"mock_response": "This is a mock response",
"guardrails": ["aporia-pre-guard", "aporia-post-guard"]
}'
You can now assign keys to users via Proxy UI
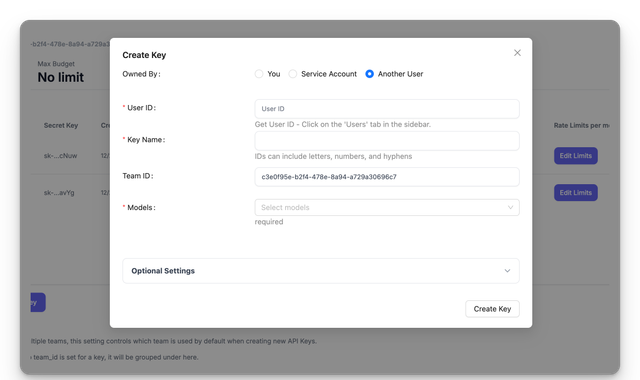
openrouter/openai/o1vertex_ai/mistral-large@2411vertex_ai/ mistral model pricing: https://github.com/BerriAI/litellm/pull/7345key management, budgets/rate limits, logging, guardrails
Get a 7 day free trial for LiteLLM Enterprise here.
no call needed
Define tiers with rate limits. Assign them to keys.
Use this to control access and budgets across a lot of keys.
curl -L -X POST 'http://0.0.0.0:4000/budget/new' \
-H 'Authorization: Bearer sk-1234' \
-H 'Content-Type: application/json' \
-d '{
"budget_id": "high-usage-tier",
"model_max_budget": {
"gpt-4o": {"rpm_limit": 1000000}
}
}'
LiteLLM was double logging litellm_request span. This is now fixed.
Logs for finetuning requests are now available on all logging providers (e.g. Datadog).
What's logged per request:
Start Here:
You can now set custom parameters (like success threshold) for your guardrails in each request.
batches, guardrails, team management, custom auth
Get a free 7-day LiteLLM Enterprise trial here. Start here
No call needed
/batches)Track cost, usage for Batch Creation Jobs. Start here
/guardrails/list endpointShow available guardrails to users. Start here
This enables team admins to call their own finetuned models via litellm proxy. Start here
Calling the internal common_checks function in custom auth is now enforced as an enterprise feature. This allows admins to use litellm's default budget/auth checks within their custom auth implementation. Start here
Team admins is graduating from beta and moving to our enterprise tier. This allows proxy admins to allow others to manage keys/models for their own teams (useful for projects in production). Start here
A new LiteLLM Stable release just went out. Here are 5 updates since v1.52.2-stable.
langfuse, fallbacks, new models, azure_storage

This makes it easy to run experiments or change the specific models gpt-4o to gpt-4o-mini on Langfuse, instead of making changes in your applications. Start here
Claude prompts are different than OpenAI
Pass in prompts specific to model when doing fallbacks. Start here
/infer endpoint. Start hereSend LLM usage (spend, tokens) data to Azure Data Lake. This makes it easy to consume usage data on other services (eg. Databricks) Start here
docker run \
-e STORE_MODEL_IN_DB=True \
-p 4000:4000 \
ghcr.io/berriai/litellm:litellm_stable_release_branch-v1.55.8-stable
LiteLLM ships new releases every day. Follow us on LinkedIn to get daily updates.